EquivAct: SIM(3)-Equivariant Visuomotor Policies beyond Rigid Object Manipulation
Jingyun Yang1* Congyue Deng1* Jimmy Wu2 Rika Antonova1 Leonidas Guibas1 Jeannette Bohg1
*Equal Contribution 1Stanford University 2Princeton University
ICRA 2024
Abstract
If a robot masters folding a kitchen towel, we would also expect it to master folding a beach towel. However, existing works for policy learning that rely on data set augmentations are still limited in achieving this level of generalization. Our insight is to add equivariance into both the visual object representation and policy architecture. We propose EquivAct which utilizes SIM(3)-equivariant network structures that guarantee generalization across all possible object translations, 3D rotations, and scales by construction. Training of EquivAct is done in two phases. We first pre-train a SIM(3)-equivariant visual representation on simulated scene point clouds. Then, we learn a SIM(3)-equivariant visuomotor policy on top of the pre-trained visual representation using a small amount of source task demonstrations. We demonstrate that after training, the learned policy directly transfers to objects that substantially differ in scale, position and orientation from the source demonstrations. In simulation, we evaluate our method in three manipulation tasks involving deformable and articulated objects thereby going beyond the typical rigid object manipulation tasks that prior works considered. We show that our method outperforms prior works that do not use equivariant architectures or do not use our contrastive pre-training procedure. We also show quantitative and qualitative experiments on three real robot tasks, where the robot watches twenty demonstrations of a tabletop task and transfers zero-shot to a mobile manipulation task in a much larger setup.
Video
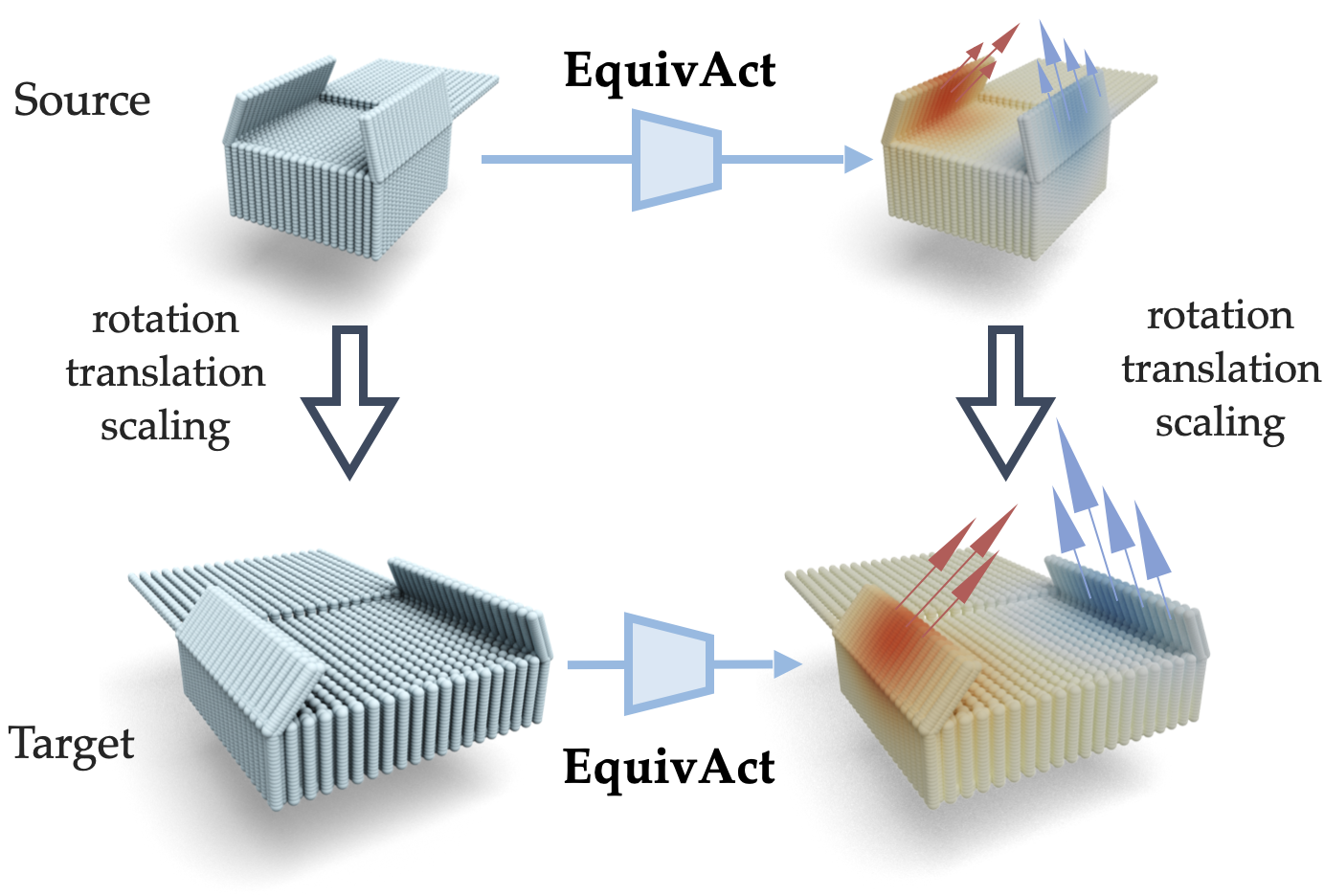
Intuition
Constructed with SIM(3)-equivariant point cloud networks, our method can take a few examples of solving a source task and then generalize zero-shot to changes in object appearances, scales, and poses.
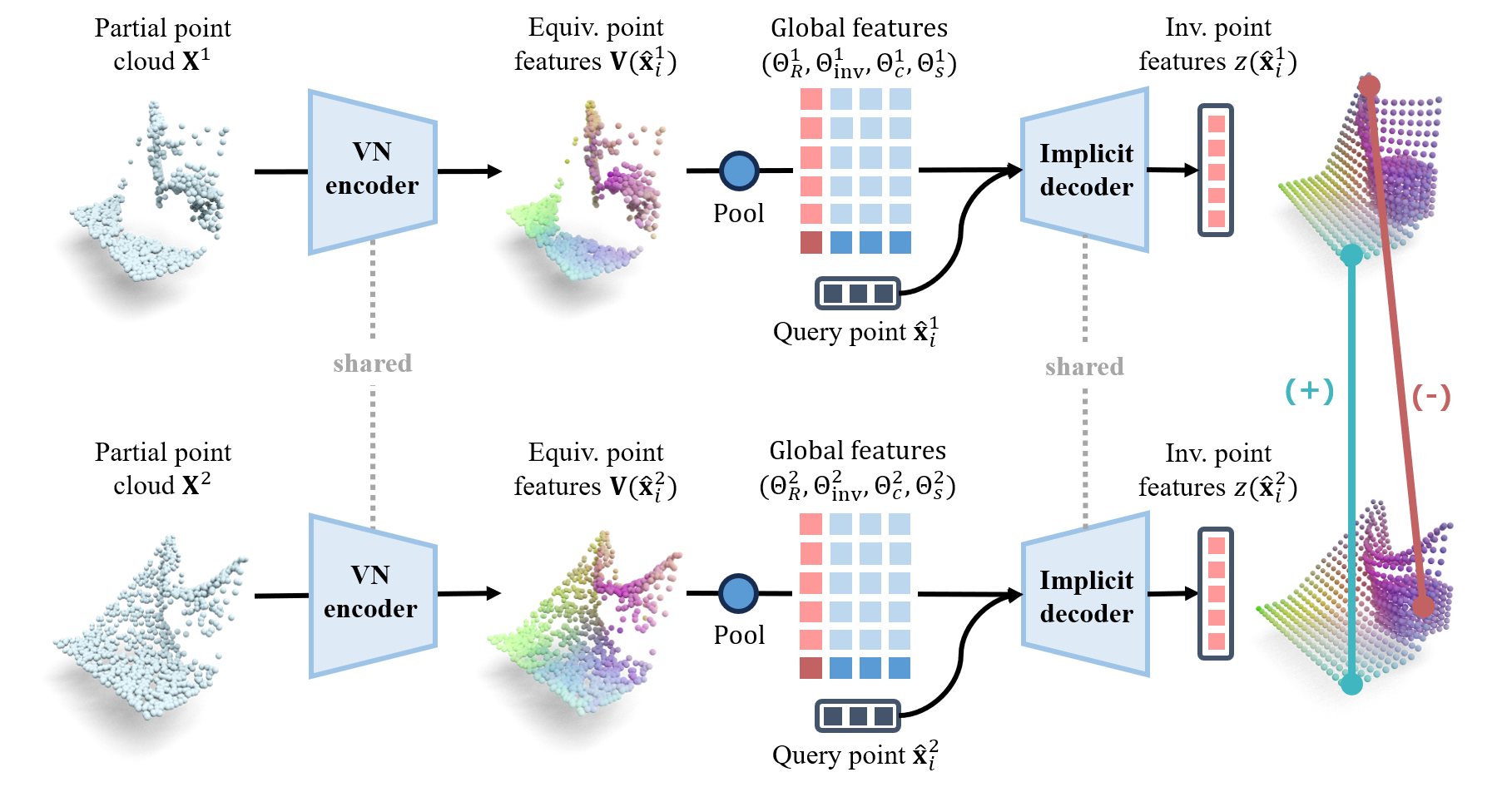
Method Overview
Our method is composed of two phases: a representation learning phase and a policy learning phase. In the representation learning phase, the agent is given a set of simulated point clouds that are recorded from objects of the same category as the objects in the target task but with a randomized nonuniform scaling. While the proposed architecture is equivariant to uniform scaling, we need to augment the training data in this way to account for non-uniform scaling. Note that the simulated data is not a demonstration of the target task and does not need to include robot actions. With the simulated data, we train a SIM(3)-equivariant encoder-decoder architecture that takes the scene point cloud as input and outputs the global and local features of the input point cloud. We use a contrastive learning loss on paired point cloud inputs during training, so that local features for corresponding object parts of objects in similar poses can be pulled closer than non-corresponding parts.
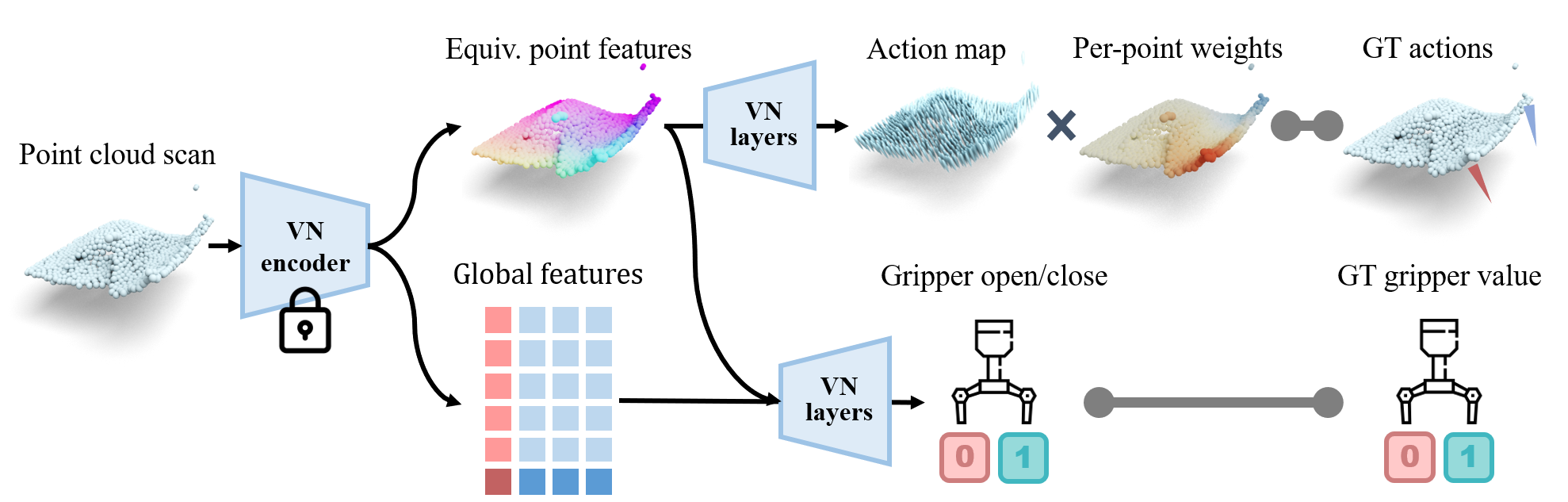
In the policy learning phase, we assume access to a small set of demonstrated trajectories of the task. This could be in the form of human demonstrations or teleoperated robot trajectories. With the demonstration data, we train a closedloop policy that takes a partial point cloud of the scene as input, uses the pre-trained encoder from the representation learning phase to obtain the global and local features of the input point cloud, and then passes the features through a SIM(3)-equivariant action prediction network to predict endeffector movements.
Results
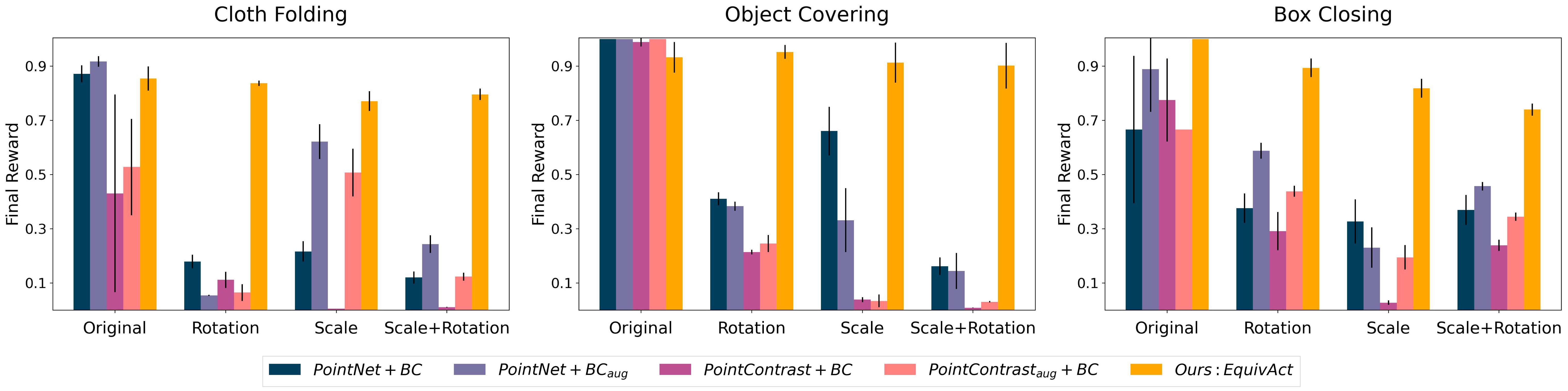
Simulated Experiments
We evaluate our method on three robot manipulation tasks involving deformable and articulated objects: cloth folding, object covering, and box closing. In simulation experiments, we show that our method performs better than baselines that do not use equivariant architectures and rely on augmentations to achieve generalization to unseen translations, rotations, and scales.
Below, we show qualitative samples of simulated demonstrations and learned sim policies executed on an object with different size and pose from the object seen in the demos.
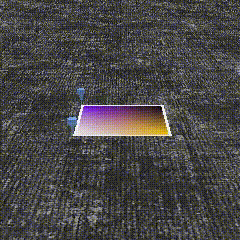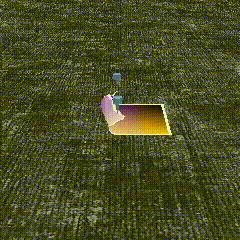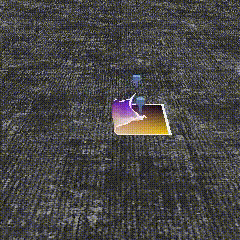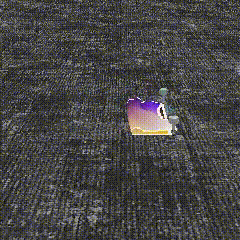


Demonstrations in Sim Experiments



Target Task Executions in Sim Experiments
Real Robot Experiments
We also run real robot experiments on the same three tasks as the sim experiments. We collected 20 human demonstrations in each task and then test the learned policy zero-shot in a mobile manipulation setup. Notably, the demos are collected on a single object in the same initial pose. At test time, the robot needs to manipulate an unseen object that has dramatically different visual appearances, scales and poses compared to the demonstrations. Below, we show a comparison of the objects that our method sees at training time (source objects) vs. the sample objects that our method might see at test time (target objects).

We show that our method performs significantly better than the best baseline in simulated experiments in all three tasks. Below, we show qualitative samples of real robot demos and real robot executions.



Human Demonstrations in Real Robot Experiments


Target Task Executions in Real Robot Experiments
Task Variations
To illustrate the generalization capability of our method, we test it on various objects and initial poses. The first row shows the Box Closing policy on two differently sized boxes placed in different initial rotations. The same policy successfully closes the boxes in both cases. In the third column, we show that the Cloth Folding policy could handle different cloths that have distinct appearance, scale, and physical properties.
Feature Visualizations
To better understand what the learned features look like, we visualize the pre-trained encoder and decoder features in all tasks. The encoder features are equivariant vector-valued features on the partial point cloud observations and the visualizations are done on their invariant components (channel-wise 2-norms). The decoder features are invariant scalar-valued features on the complete objects. We run PCA on feature values within each task to obtain RGB values for visualization purposes. All point clouds are aligned to the canonical pose for visualization. Top two rows: Objects of different shapes viewed from different camera angles but at the same poses. Both encoder and decoder features show strong correspondences within each state due to the contrastive learning. Bottom row: Objects from a different state. The features become different from the above rows.

BibTeX
@inproceedings{yang2024equivact,
title={Equivact: SIM(3)-Equivariant Visuomotor Policies beyond Rigid Object Manipulation},
author={Yang, Jingyun and Deng, Congyue and Wu, Jimmy and Antonova, Rika and Guibas, Leonidas and Bohg, Jeannette},
booktitle={2024 IEEE International Conference on Robotics and Automation (ICRA)},
pages={9249--9255},
year={2024},
organization={IEEE}
}